

link to writeup on algorithm
Play with the algorithm (break stuff!) as implemented in etcd
Why?
Failure resiliency and “uptime”are two hallmarks of good sysops. In addition, much of operations level goals can be boiled down to:
Raising the mean (average) time between failures (MTBF)
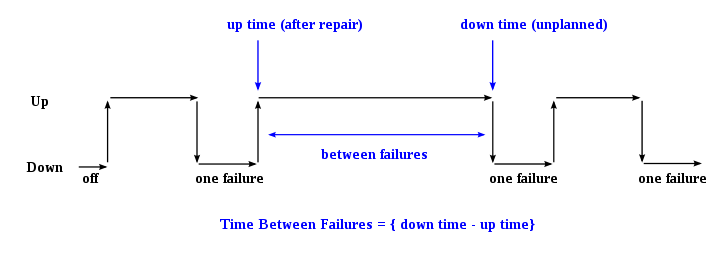
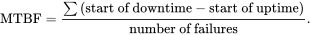
Lowering the mean (average) time to repair (MTTR)
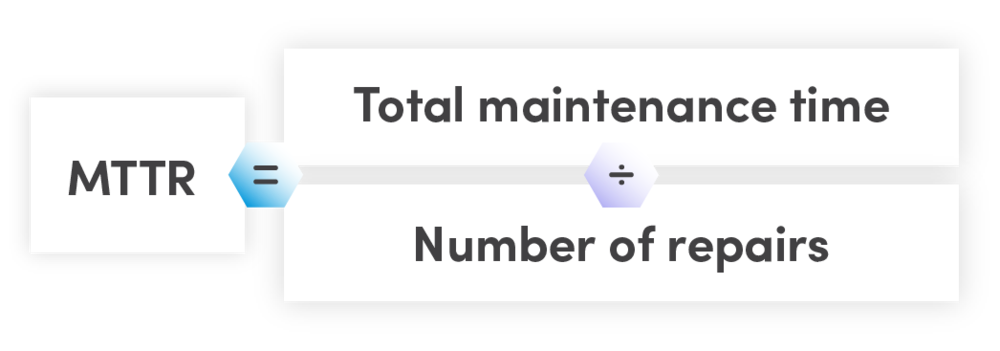
Software containerization, and container orchestration with Kubernetes can be good at achieving both of these due to its use of the rafting algorithm for failure resiliency and quick and automated resolution of failures.
The rafting algorithm used by etcd, the backing key/value store for kubernetes, allows a cluster of five-“many” computers to dynamically form “consensus” even in a chaotic environment. A computer will mark itself as a candidate to be elected leader if one it has not had communication with a lead for a period of time, and once a leader is elected the group “rafts” together with consensus towards its common goal.
Tikam02 DevOps-Guide Kubernetes
Tikam02 DevOps-Guide Kubernetes Advanced
Related:
Previous:
