
Synopsis:
Powerful deep learning is poised to become much more accessible given the increased availability of cheap and powerful hardware designed for fast, highly-parallel computations on neural nets.
“Toe in the water”:
I’ve been trying to get my toe into the water in understanding machine learning, and I’ve created an account on the competitive data science site Kaggle (+) to start snooping and seeing what’s around.
The available data sets and competitions are certainly interesting in both technical implementations and scope.
Something that I’ve also found immediately interesting about the state of Kaggle and data science currently is the deep learning power currently available for data science using consumer video game graphics cards, or GPU‘s.
Anyone paying attention to cryptocurrencies the past few years probably noticed something interesting: GPU’s are a lot better at cryptocurrency “mining” (or solving a large series of math problems to “mine” and provide ownership of an unclaimed block of currency) than CPU’s.
This is effectually because these “graphics” chips are designed to do many small math problems in parallel with many small discrete processors, whereas a “big and fast'” CPU is generally limited to following one track of execution at a time.
“floats” and GPU architecture:
In addition, GPU’s have generally been designed with special hardware that enables faster calculations on decimal, or “floating point numbers“, that are important for computer graphics.
Neural Nets:
Due to fortunate coincidence, doing many operations quickly and in parallel on floating point numbers also seems to be great for working with neural nets (+) as well.
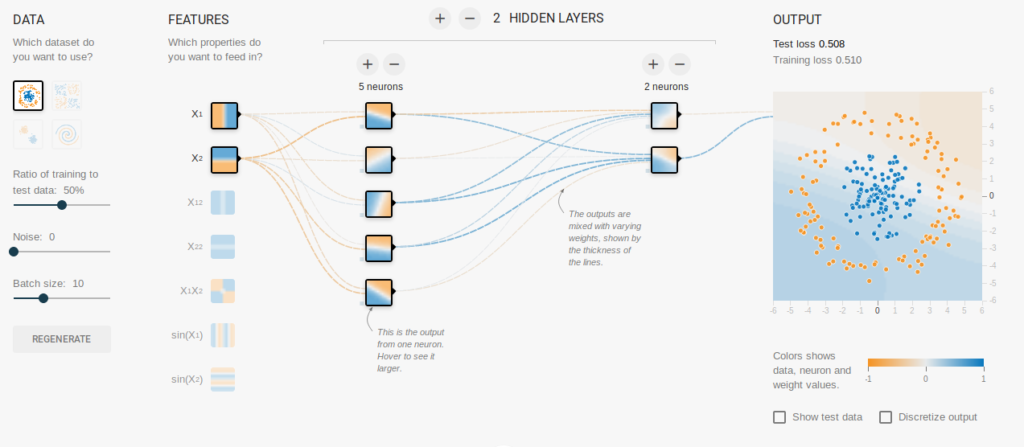
Generally, the idea with the neural nets used for Machine learning is that numerous virtual “neurons” are exposed to stimulus with a large labeled training set of data. As the neurons are exposed, a large amount of math is performed to “back-propagate” information gleamed from observed stimuli through the various layers of the neural net as it learns. By performing these calculations, a neural net has been “trained” to be able to recognize properties of data of a certain pattern, and can begin to make powerful inferences when exposed to new stimuli.
Neural nets have proven extremely powerful in a wide variety of uses, and have already enabled advances in AI such as allowing Google’s DeepMind to beat the former world champion at GO, an achievement that some thought wouldn’t happen for at least another 10 or so years:
Hardware for Machine Learing:
A Kaggle user participating in data science competitions has seemed to have found a sweet spot in using consumer hardware for training neural nets with the RTX 2070 using PyTorch. He describes the RTX 2070 as a great GPU for deep learning because of its high memory bandwidth, its use of tensor cores to accelerate matrix manipulation math essential to Machine Learning, and its ability to run extremely fast and parallel computations on reduced precision 16 bit floats instead of the normal 32 bits. Together, these properties allow the card to perform a large number of calculations on “floating point” neural net values extremely rapidly.
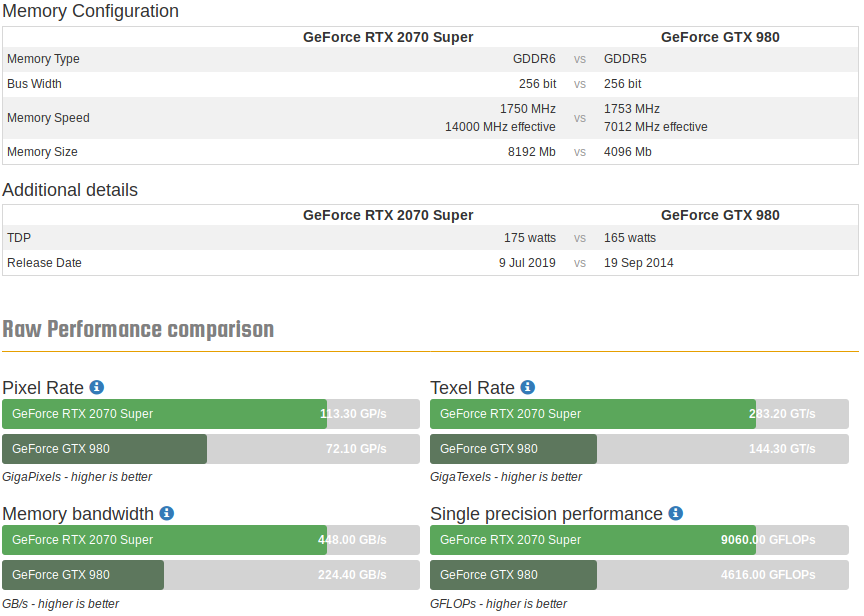
The increased memory bandwidth, floating point performance (single precision performance),
and ability to process a larger volume of computations using lower-precision 16 bit floats
make it a powerful card for deep learning
Examining the lineup of emerging dedicated hardware for deep learning such as Tesla’s Neural Processor, Intel’s nervana, and Amazon’s Inferentia chip, It seems that going forward extremely good memory and cache performance and the performance of fast, simple operations on floating point numbers with such dedicated hardware will allow for very powerful AI models to be trained and used in the future.
software, hardware and “rapid prototyping” data models:
The aforementioned kaggle user has seemed to also have found that the libraries and software support using NVIDIA GPU’s seems to be the best option around for Machine Learning currently.
Having a fast GPU allows for quicker “rapid prototyping” of training and working with data models.
In addition, he seems to have a preference for Facebook’s PyTorch over Google’s TensorFlow, which will probably impact my projects and how I seek to self-educate in data science and machine learning going forward.
More resources:
The 100 page machine learning book/
Hands-Machine-Learning-Scikit-Learn-TensorFlow
https://github.com/chenyuntc/pytorch-book
![]()