The authors introduce a new index of the business cycle that uses the Mahalanobis distance to measure the statistical similarity of current economic conditions to past episodes of recession and robust growth. Their index has several important features that distinguish it from the Conference Board’s leading, coincident, and lagging indicators. It is efficient because as a single index it conveys reliable information about the path of the business cycle. Their index gives an independent assessment of the state of the economy because it is constructed from variables that are different than those used by the NBER to identify recessions. It is strictly data driven; hence, it is unaffected by human bias or persuasion. It gives an objective assessment of the business cycle because it is expressed in units of statistical likelihood. And it explicitly accounts for the interaction, along with the level, of the economic variables from which it is constructed.
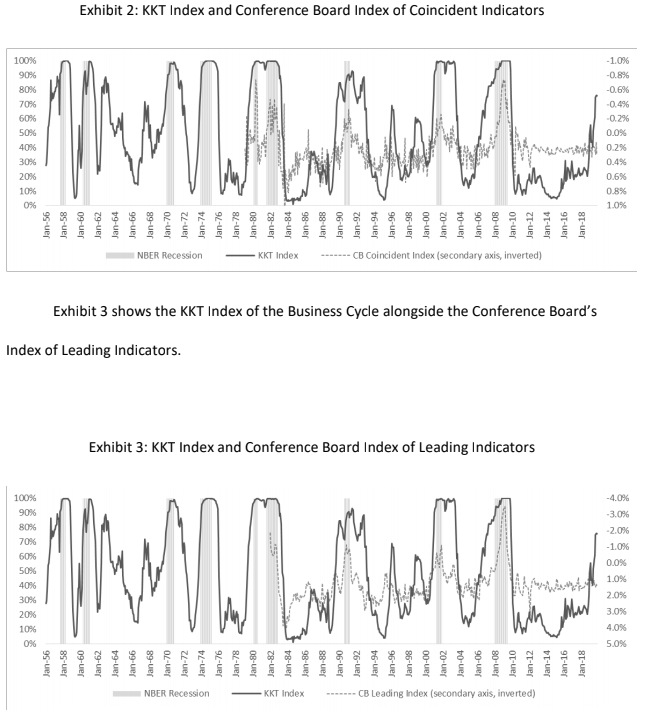
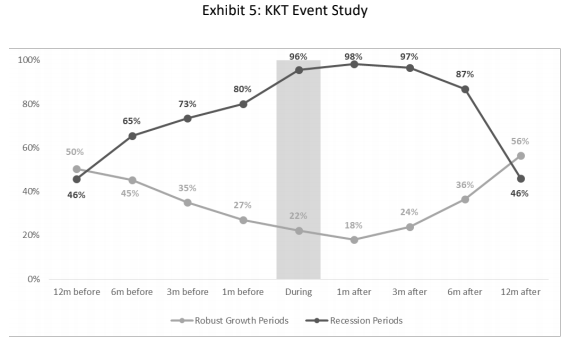
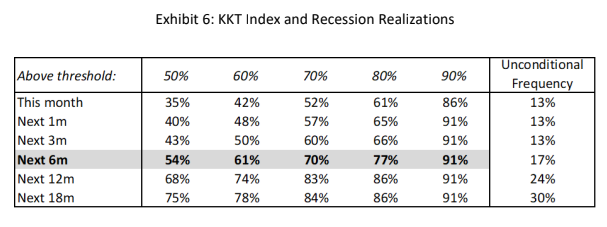
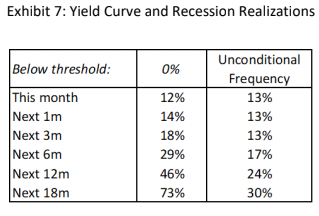
Exhibit 2 presents a time series of our index of the business cycle (solid black line), which we refer to as the KKT Index, beginning in January 1956 and ending in November 2019 (the period for which all observations are out of sample). This line measures how much more likely it is that the conditions at any point in time are associated with recession instead of with robust growth. The periods defined as recessions by the NBER are indicated by the shaded bars.
As of November 2019, the value of the KKT index was 76% (left axis), which means that considering either recession or robust growth, this set of conditions is more closely associated with recession 76% of the time (and with robust growth 24% of the time). Put differently, a recession is more than three times as likely as robust growth.
An index level of 76% does not necessarily mean that the economy is currently in recession. Rather, we should interpret it as an indication of the potential for the economy to enter recession in the foreseeable future.
Given historical guidance, the index should be close to 100% when a recession is imminent or underway.
While my knowledge is at best surface level for many off these topics, the CNCF’s CTO Chris Aniszcyk has some interesting writings on what goes on in the development, governing, and organization of such substantial open source communities:
The rafting algorithm used by etcd, the backing key/value store for kubernetes, allows a cluster of five-“many” computers to dynamically form “consensus” even in a chaotic environment. A computer will mark itself as a candidate to be elected leader if one it has not had communication with a lead for a period of time, and once a leader is elected the group “rafts” together with consensus towards its common goal.
1 and 3 are areas I’ve been thinking about a lot recently.
Upon reflection, I really wish I had taken more time in high school and college for practicing writing and getting good feedback on how to improve. I don’t really think there’s any substitute for this kind of practice with back-and-forth feedback from an experienced writer.
Economics can be pretty easily digestible though. The textbook learning is really important, but it can be fun too to learn “economic thinking” in a more low stakes way as well. NPR’s Planet Money podcast is a great example of this, including zany stories such as “the tale of the onion king” when a single trader was able to corner the market for onions one year. There’s also great news reporting through an “economic” lens of thinking, including practical stuff such as news on tech and business (if you’re interested in that too, I guess).
Update: This is the textbook for a microeconomics class I started earlier (but couldn’t complete due to scheduling conflicts):
Michael Parkin: Microeconomics (13th ed.)
ISBN: 978-0-13-474447-6
I think it really does a good job of bringing up economic concepts in very accessible and thought-provoking ways.
It also does well to inspire in the reader the process of “economic thinking” in framing many different types of issues as economics ones. I think for this alone the contents of the book are of value to most readers.
This is a game I made as part of a class assignment in the summer of 2017. I wrote it in C using structs, pointers, etc. , running “bare metal” on the Game Boy Advance with no operating system.
While modern, or “high level” , languages have often “abstracted away” such nitty-gritty details of hardware through fancy software trickery, its still important to have an appreciation for how hardware works in order to write better and more efficient code.
Much like how pilots who train how to fly in a Cessna can have a better “aircraft feel” than those that train in simulators even when working with larger aircraft, a programmer can make costly algorithmic mistakes if he/she’s only worked with higher level languages and is not familiar with what’s happening “under the hood”, as others have noted+
I’ve worked mainly with Java in my computer science courses for data structures and algorithms and Python for AI, but I’ve also enjoyed the opportunity to write things such as linked lists, memory allocation, paging algorithms, etc. in C as part of my college curriculum.
I’ve also learned the fundamentals of computing working up to logic and circuits from the transistor level, to processor design and assembly language, to memory caching, instruction pipelining, etc. It’s much harder to keep track of the pointers, memory, and debugging with tools like valgrind when working with C, but it can ultimately be very rewarding to work at the lowest levels of computing for being able to write “go fast” code, as well as for practice and educational purposes.
Emerging languages like Rust are beginning to offer some of the speed advantages akin to C/C++, but the affordances the language offers to programmers makes it easier to write more complicated code with less memory safety mistakes, pointer issues, etc.
For instance, in the talk below, a poorly implemented data structure in Rust performed better than a well written one in C because the backing data structure implementations were able to be written with more complicated and performant algorithms.
Tech Details:
Most of the display work is done through Mode 3 and Direct Memory
Access (DMA) (for the image, background, etc) as per the scope of this
assignment. This is much more demanding on the GBA than doing
sprite-based graphics, so some performance considerations were made to
keep the game running smoothly.
The vertical pipe obstacles are generated by DMA’ing a green pipe, and a trailing blue background color behind it constantly to keep the pipe moving to the left while “erasing” its previous position from the frame buffer in memory.
The score text is only drawn after every “screen wipe” by the pipes
rather than every frame. The score text draws pixel-by-pixel and would
have been too expensive to re-draw every frame without slowdown or
complicated optimization.
Because the GBA doesn’t have native floating point capability (i.e. decimal numbers for movement speeds, etc.), the bird’s velocity is only updated on certain frames as to allow for a kind of “fractional” change in velocity over time. This means that gravity and velocity changes from movement input only “kick in” on certain frame intervals.
I definitely would have implemented input buffering of some kind (so that a “flap” button press could be registered at any time with a press, and will not keep adding to the velocity if held down) if I had more people play-test this before completion.
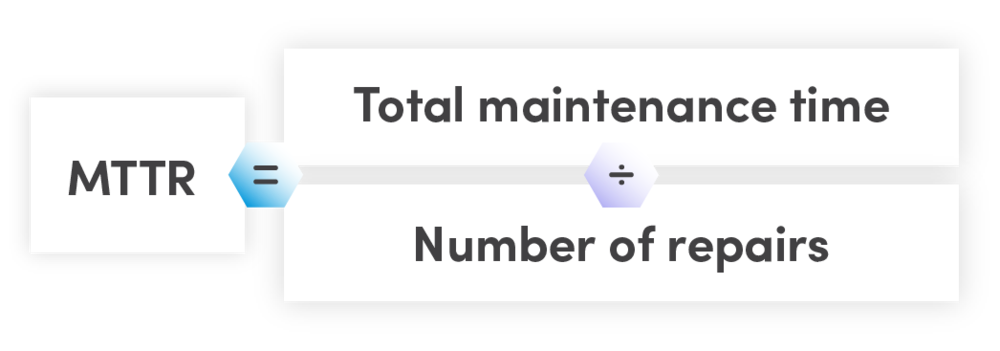
EDIT: Most readers should use EasyEngine instead of this guide for a more up to date and easy to administer Docker NGINX+Wordpress setup similar to the one detailed here.
You can install it on a rented virtual private server from a provider like DigitalOcean very easily, and it will likely be cheaper, more powerful, and more distinguished to search engines than common shared WordPress hosting platforms.
For this site, I found it very easy to register the domain name foobarbat.dev with Google Domains for DNS and set it to point to the IP Address of my DigitalOcean server. If you have a domain name you’d like to own, it’s a good idea to snag it from Google or another registrar like GoDaddy. You can later set it to forward to whichever platform you decide to use for your website.
If you’re interested in learning about Docker containers or how a more manually configured stack works, please continue reading.
So, I have a cloud server on DigitalOcean that I pay 15$ a month for. For this, I get a global IPV4 address, 2GBs of memory, 2 CPU’s (shared), and 60GBs of storage.
I’ve played around with Amazon Web Service‘s ECS for Docker containers, which are pieces of software that are packed into little ‘containers‘ that you can run [almost] anywhere, and cloud computer hosting before, but by far I’ve found DigitalOcean to be much, much easier for what I want.
What I want just happens to be just a simple playground where I can run server stuff and Docker containers, including (but not limited to) small video game servers like Minecraft and such.
my home away from home
Choosing an Operating System
I was using an operating system called RancherOS earlier (Edit: CoreOS+ seems to be more popular now), which is designed to be as bare-bones as possible and to run just about everything in a container.
If I was doing some kind of large deployment with many servers this would be useful, but I found that it was a bit too bare-bones for a general purpose server. I switched back to Ubuntu Linux to have something that could be a bit more fleshed-out.
If you wanted something that would be more stable with less need for updating, you could go with CentOS (equivalent to Red Hat Linux) instead.
I started by installing the Docker container engine on the Ubuntu server. I then began playing with things such as putting an obscure videogame server in a Docker container to make it easier to update and run. The process for doing this was very similar to what would be needed for containerizing just about any Windows .NET-based application.
The nice thing about a server like this is you can run justaboutanything pretty quickly with Docker. With Docker containers, you can run just about any software “in place” with very little need for configuration. Instead, the onus is on software developers or community members to ensure dependencies, default configurations, and data access are already setup in a ready-to-run container. In addition, upgrading is usually much easier: just stop the running container and run the newer one in its place.
With all this being so nice, I thought: why not build a website?
The Website
Initially, I just got a DNSrecord for matthew.krupczak.org to point to the IP address of my Digital Ocean Server. I then ran the Docker WordPress container on my server and Boom! I suddenly have a website with almost no configuration required (but no HTTPS).
What the setup looks like when starting up. Easy peasy
A Docker WordPress stack (with HTTPS)
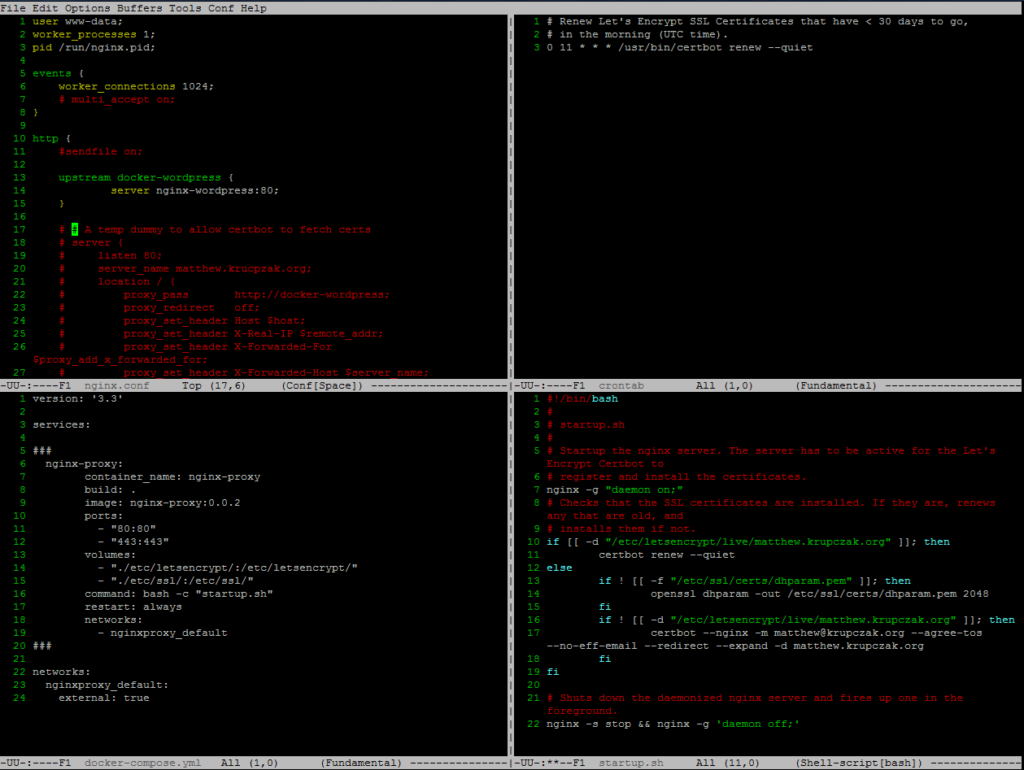
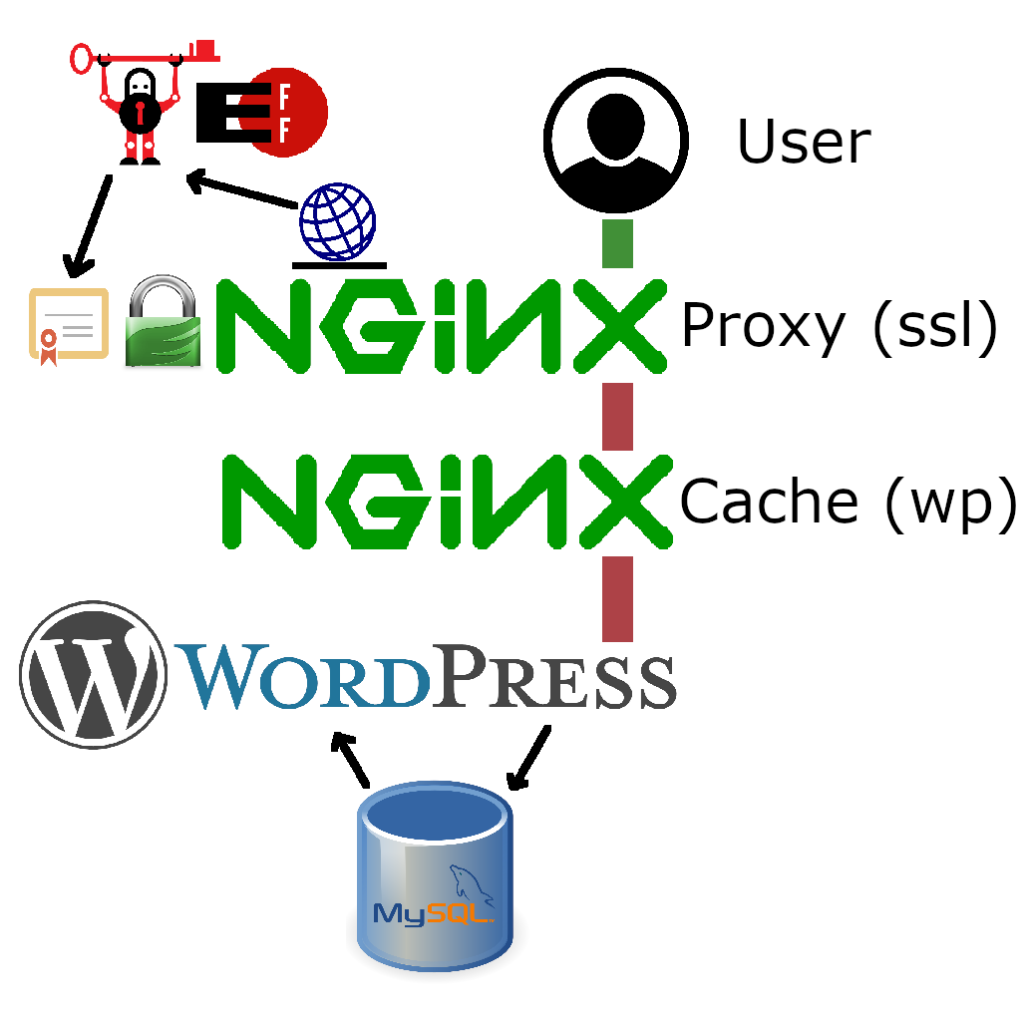
Hacking in the terminal with Emacs Top-left NGINX proxy config Top-right cron job for certificate renewal Bottom-left docker-compose file for NGINX proxy Bottom-right startup script for NGINX (not shown) Dockerfile recipe for building custom version of NGINX
Using this guide, I attempted to add HTTPS encryption to my site. I used the free encryption certificates provided by the EFF with let’s encrypt and Certbot for auto-renewal. The added benefit of this setup is it puts NGINX in front of the website at two different layers as a reverse proxy and an http cache. The latter allows the stack to serve traffic faster and at a much larger volume than would be possible with WordPress alone.
Layers!
Servers have… Layers!
This type of configuration is common among internet infrastructure. Typically, an NGINX (or HAProxy) instance allows for higher-level caching, load balancing, or reverse proxying. It then typically feeds into one or more instances of a feature-rich application such as WordPress running on Apache.
In addition, SSL termination and certificate management is wholly contained in the top “reverse proxy” NGINX container. This allows for a more simple configuration for the rest of the stack.
Snags
WordPress
In writing my own docker compose file based on this guide, I forgot to switch from “wordpress:latest” to “wordpress:5.2.3-php7.1-fpm”. This left me with a frustrating 502 bad gateway error from NGINX, and it took me a while to debug. By digging through the containers, I figured out that top proxy (handling HTTPS) was working fine but the HTTP cache wasn’t working because it was incompatible with the vanilla WordPress image
Certbot
In “startup.sh” Certbot was configured for www.matthew.krupczak.org as well as matthew.krupczak.org. There is no DNS entry for www.mathew.krupczak.org, so I expected that Certbot would fail cleanly and install the working matthew.krupczak.org. Instead, Certbot was incredibly picky and would look like it was installing, but would instead fail everything.
In addition, the provided startup script may have failed to generate DHparams before running Certbot the first time. To fix this, I just ran command manually and modified the provided startup.sh to give it an extra spot where it would attempt to generate them.
Closing Thoughts:
Why go through all this effort? Well, for fun and…
You could use Docker to set this WordPress stack (or something like it) up on DigitalOcean or any other cloud for as little as $5 per month with free HTTPS certificates, full control of the site and the server it runs on, and a place where you can host any other kind of container you’d like to run.
In addition, hosting your own WordPress server can allow your website to have better performance and to be more distinguished to search engines.
(note: you can probably upgrade the NGINX, WordPress, and MariaDB versions from those in the guide. I opted to use MySQL instead of MariaDB for my site.)
I think for anyone who’s built or worked on something, there’s a tendency to wonder if something could have been done better or what could have been done differently.
Gabe Newell of Valve has said that his favorite game from his company was Portal 2, if only because he was much more involved in the development of all the other games Valve has created. He said while playing the company’s other games he would notice areas where content got cut or things didn’t go perfectly according to plan.
If you’ve built a decent amount of things, you may come to a point of reflection where you have that one thing you’ve built that works, but you’re unhappy with. For me, it’s this piece of code:
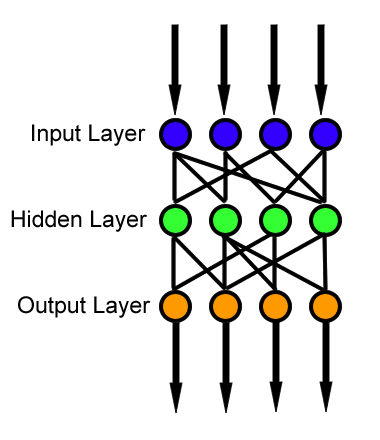
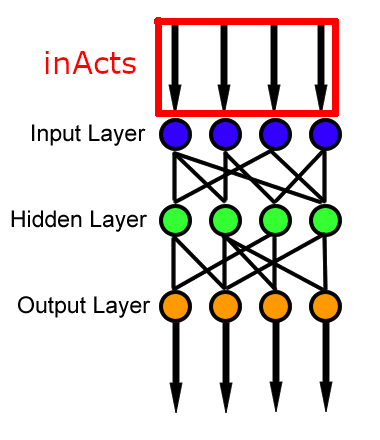
This was for a project in my intro to AI class where we were writing an implementation of a feed forward neural network (woah!). This sounds really complicated, but basically all it was was stringing along a couple of nodes (perceptrons or like, simple neurons almost like you have in your brain) like the picture below and then doing some fancy math to describe how a value moves through the network.
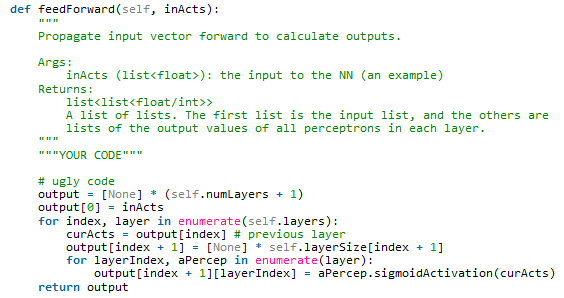
So, This function described how the values would propagate from one layer to the next (for instance, from the blue layer to the green, or the green layer to the orange).
How did I know this code was bad?
I had a close friend who was returning from a sports tournament and was trying to complete the assignment the day it was due. We had our textbooks open to all the formulas we needed, and I was practicing some form of “clean room coding” where I would help him understand the concepts and algorithms without either of us seeing each other’s code. Everything was going perfect until we reached …
Do you understand how this code works? Because I didn’t (it haunts me)
Also, “””YOUR CODE””” # ugly code
So, in a moment of pure horror and frustration, we broke the “clean room” to both look over this piece of code. We spent maybe 15-20 minutes trying to re-implement it, but none of the attempts seemed to work. It seemed that we couldn’t really figure out how this code worked, and couldn’t seem to replicate its effects.
If this (or something like it) was actually running as live code somewhere and causing errors, I’m sure someone would be pulling their hair out.
What can one do in a situation like this? Well, you can start from the input and the output of the function and try to figure out how it works:
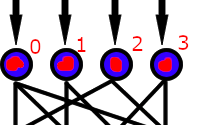
Cool, so uh what? This means that we are given a list of decimal values (like 3.14159…) that represents the input values for our input layer like so:
And, we also see:
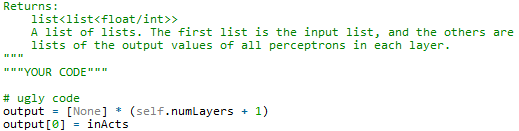
Cool! So now we know that our function outputs a 2 dimensional array (essentially, an array containing arrays) where the number of arrays is the number of layers plus 1 (n+1). We also know that inActs is the same as the 0th (computers count from zero) array of our output. So, we’ll make a guess:
This looks pretty good! Lets assume this is true for now and see if we can figure out the rest:
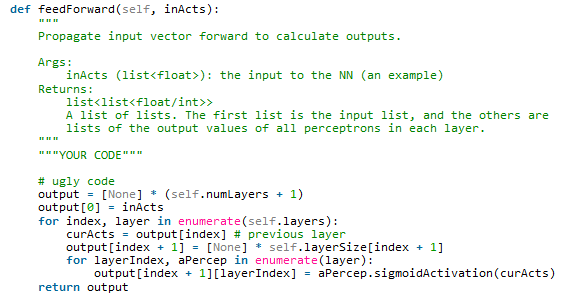
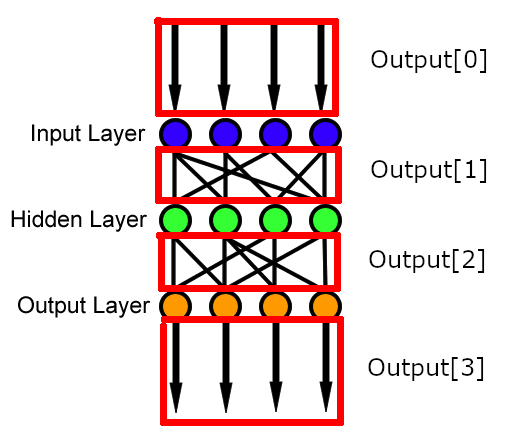
Ooh, a scary nested for loop. For the top one, we should try to think of a real example for it to run on, that way we can think about how it will start and when it will stop. So, if we have 3 layers like in our picture, it will count: 0, 1, 2.
Broken up, it doesn’t look as scary (I hope?)
So, if we pretend (in our heads) to run it on 0, 1, and 2, we can see it will start at Output[0], then go to Output[1], then finally Output[2]. We can also see that at each step, it “looks ahead” and builds the next output array. At 0 it builds the 1th array, at 1 it builds the 2th array, and at 2 it builds the 3th array.
Whew.
So now, let’s look at the nested for loop, or the loop that occurs each time the top loop occurs:
We also see that with the for loop looking for a (layerIndex, aPercep in enumerate(layer)), so this means it iterates through a layer and gets a layerIndex starting at zero and a perceptron object that is nicknamed “aPercep” for your reading pleasure. It probably looks like this:
So if we look at that code block again…
We can see that it’s building the index + 1 th layer by taking in its input weight (from curActs, or, the previous layer), shoving it through the perceptron à la the secret meat grinder that is the sigmoid activation function, and then putting it as the output value of the perceptron for every perceptron (0, 1, 2, 3 in our example) in the layer. Subsequently, this output value from the perceptron is used as an input for the perceptrons in the next layer.
Now if we did a run through in our heads, we could see that these two lines would be building the activation values for the next layer, then it would end and the top for loop would increment, and then finally we would use the values we just generated to build the next layer and repeat until there are none left.
Cool!
So, if this code works what’s the problem?
Well, I wrote the code only about one or two days ago and couldn’t figure out how it worked in 20 minutes. When you’re “in the zone” and writing code like this, it can seem like it makes perfect sense at the time but can look horrible when you come back at it later. I think this may be why some people have the idea “everyone else’s code is ugly” because maybe, well, everyone’s code is ugly.
Some people subscribe to the idea of “self documenting code” or, the idea that code should be written in an intuitive way (with variable names, etc.) so that others can read along with it and get an inkling of what it does. I’m not generally such an optimist, so I like to add in the occasional comment for when I feel dumb and am looking over it later.
In a later post, we may take a look at how this code could be written in a different way so its a bit easier to read and understand.
Edit: A commenter ceiclpl on reddit wrote a great alternative implementation of this function:
I really wanted to clean this up, and discovered it translates well into understandable code:
def feedForward(self, acts):
outputs = [acts]
for layer in self.layers:
acts = [aPercep.sigmoidActivation(acts) for aPercep in layer]
outputs.append(acts)
return outputs
Which much better describes what it’s doing. It just iteratively applies the activation function on a list, over and over, and retains the intermediate values.
I think this code example is also a great demonstration of the “programming as a means of expression” concept.
I’m used to living in “Java/C -land”, programming where objects are first class citizens and instead of making use of Python’s syntactic sugar for working with arrays, I did it the old-fashioned way with array indexing.
Thank goodness for our Pythonista ‘s out there, they’re a different breed
The heartbleed OpenSSL vulnerability in 2014 (affecting Google, Facebook, etc.) exposed another issue: sometimes widely used open source software doesn’t get the love it deserves in terms of monetary or code support from those that use it.
If you’re using open source software at your company, then this software could be considered in economics terms as a complement* to your company’s product, where its availability, quality, and ecosystem directly bolsters it.
Below, Joel Spolsky writes on how smart companies** in the past have strategized to further their business interests by supporting and proliferating complements to their products, or otherwise “commoditizing their complements” to great results:
*In economics, a complementary good is a good whose appeal increases with the popularity of its complement. I.e. complementary goods are often consumed along with each other
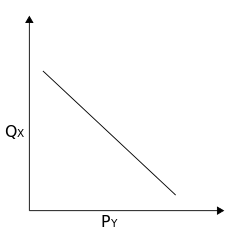
Complementary goods exhibit a negative cross elasticity of demand: as the price of goods Y rises, the demand for good X falls.
For example, if you sell peanut butter and the price of jelly goes down, then it’s cheaper for people to make a peanut butter and jelly sandwich. The demand for peanut butter will increase, and you could raise prices.
In this example, we can imagine it would be a peanut butter company’s dream come true if the price of jelly lowered (or even became free).
If you’re using open source software at your company, think of your company’s proprietary product as peanut butter and open source software as jelly. From a strictly financial sense, it may make sense for you to “lower the cost of jelly” by supporting open source software with cash or coders.
By doing so, you can improve the quality and community around the tools you rely on, increase demand, availability, and functionality of your product for a fraction of the overall cost, and you can raise prices and profits in turn.
**In economic terms, open source back-end infrastructure can be considered as a complement to proprietary front-end software product.
Smart companies proliferate complements to their products in order to increase demand.
Therefore, it’s easy to see why so many companies have a vested interest and have banded together to ensure the success of open source software and organizations like the Linux Foundation and the CNCF.
It’s important to note that companies aren’t contributing to open source for purely altruistic reasons. Recent research from Harvard shows that open source-contributing companies capture up to 100% more productive value from open source than companies that do not contribute back.